How to Scrape LinkedIn Job Postings with Python: A Step-by-Step Guide

How to Scrape LinkedIn Job Postings with Python: A Step-by-Step Guide
LinkedIn is the world's largest professional network, making it a goldmine for data on job market trends, company hiring patterns, and employment opportunities. Whether you are a recruiter, a market researcher, or a developer building a job board aggregator, automating the collection of this data can provide a significant competitive advantage.
In this article, we will walk you through how to build a robust LinkedIn Job Postings Scraper using Python. We will cover how to handle common challenges, such as infinite scrolling and anti-bot protections, using the Apify Residential Proxies.
Tip: Don't want to build it from scratch? Check out the ready-to-use production-grade LinkedIn Job Postings Scraper Actor on the Apify Store.
Why Scrape LinkedIn Job Data?
LinkedIn Jobs page
Scraping LinkedIn data opens up a wide range of powerful use cases:
- Lead Generation: Create highly targeted lists based on job titles, industries, or specific technical skills to drive personalized and effective outreach campaigns.
- Competitor Intelligence: Gain insights into the competitive landscape by tracking your competitors' hiring patterns, growth trajectories, and organizational structures.
- Recruitment & Sourcing: Go beyond basic keyword matching to discover passive candidates and build deep talent pipelines filled with the exact skills you need.
- Market Research: Monitor emerging industry trends, skill demand shifts, and the geographical distribution of talent.
- Academic Studies: Gather data for analyzing labor market dynamics, professional migration patterns, and economic correlations.
In short, if valuable data exists on a public LinkedIn page, ethical web scraping is a scalable method for aggregating it for business or research insights.
The Challenges of Scraping LinkedIn
LinkedIn is known for its strict anti-scraping measures. If you try to scrape it with a simple script, you will likely face:
- IP Bans: Frequent requests from the same IP address will trigger rate limits.
- Infinite Scrolling: Job lists load dynamically as you scroll, complicating pagination.
- Login Walls: Many pages require authentication, which risks flagging your personal account.
To overcome these challenges, we will utilize the Apify SDK for Python and Residential Proxies, which enable us to route requests through legitimate devices, making our traffic indistinguishable from real users.
Prerequisites
Before we start, ensure you have:
- Python 3.8+ installed on your machine.
- An Apify Account (you can sign up for free).
- Basic knowledge of CSS selectors.
Step 1: Setting Up the Environment
We will use the Apify Python SDK to manage our scraper's execution and storage. You can start by using the Apify CLI to create a new boilerplate project.
npm install -g apify-cli apify create linkedin-scraper -t python-start cd linkedin-scraper
Install the necessary Python libraries:
pip install apify httpx beautifulsoup4 httpx-socks
apify: For managing the Actor's lifecycle and storage.httpx: A modern, asynchronous HTTP client.beautifulsoup4: For parsing HTML content.
Step 2: Handling Infinite Scrolling and Pagination
LinkedIn's job search page uses infinite scrolling. Instead of trying to simulate scroll events (which is slow and flaky), we can reverse-engineer the hidden internal API used by the frontend.
# The base URL pattern list_url = f"https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search"
This approach allows us to scrape thousands of jobs without ever needing to render the full page in a browser, significantly speeding up the process.
Step 3: Implementing Residential Proxies
This is the most critical part. To avoid getting blocked, you must use high-quality proxies. The LinkedIn Job Postings Scraper is robustly designed to use Apify Residential Proxies when available, with a fallback mechanism for local testing.
Here is how we configure the httpx.AsyncClient to use a specific proxy country (e.g., US) to ensure we see relevant job data:
# Handle Proxy Configuration proxy_country = actor_input.get('proxyCountry') proxy_url = None try: # Attempt to use specific Residential Proxies (e.g., US) proxy_configuration = await Actor.create_proxy_configuration( groups=['RESIDENTIAL'], country_code=proxy_country ) proxy_url = await proxy_configuration.new_url() except Exception as e: Actor.log.warning(f"Residential proxy unavailable: {e}. Falling back...") # ... fallback logic handles local execution safely ... # Configure the HTTP client client_kwargs = {'timeout': 30.0} if proxy_url: client_kwargs['proxy'] = proxy_url async with httpx.AsyncClient(**client_kwargs) as client: # ... scraping logic ...
By allowing users to specify a proxyCountry, the scraper can view job listings exactly as they appear to a user in that region.
Step 4: Scraping and Parsing Data
Once we have the HTML, we use BeautifulSoup to extract key details, such as the Job Title, Company Name, Location, and Posting Date.
def get_job_data(soup):
return {
"title": soup.find("h2", "top-card-layout__title").get_text(strip=True),
"company": soup.find("a", "topcard__org-name-link").get_text(strip=True),
"location": soup.find("span", "topcard__flavor--bullet").get_text(strip=True),
"job_url": soup.find("a", "topcard__link")['href'],
# ... more fields ...
}Running the Actor
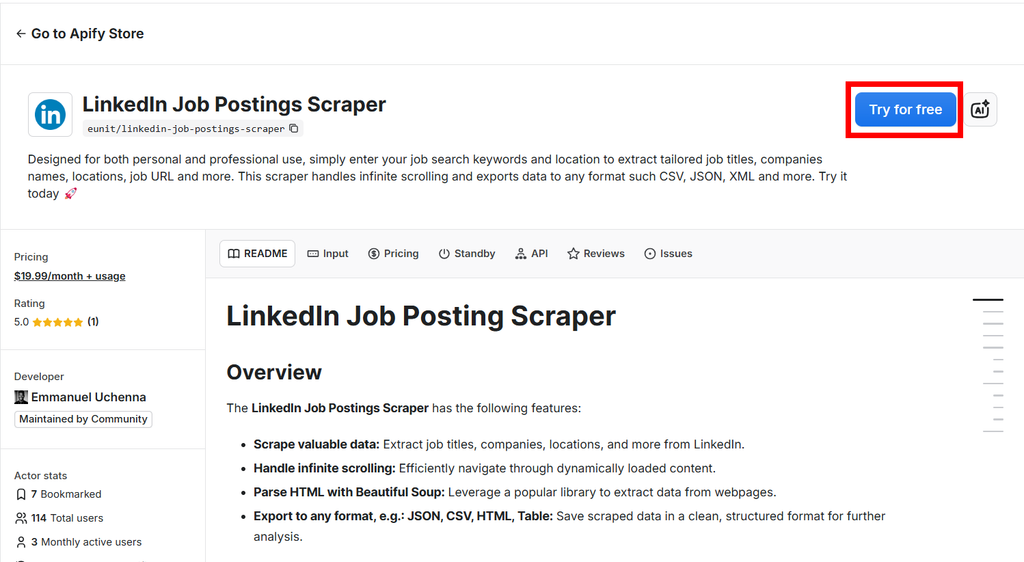
LinkedIn Job Postings Scraper on Apify
You can run this scraper directly on the Apify platform (recommended). Go to the LinkedIn Job Postings Scraper page.
- Go to the LinkedIn Job Postings Scraper page.
- Click Try for free.
- Fill in your input:
- Keywords:
Software Engineer - Location:
United States - Proxy Country:
US(Recommended for US jobs)
- Keywords:
- Hit Start.
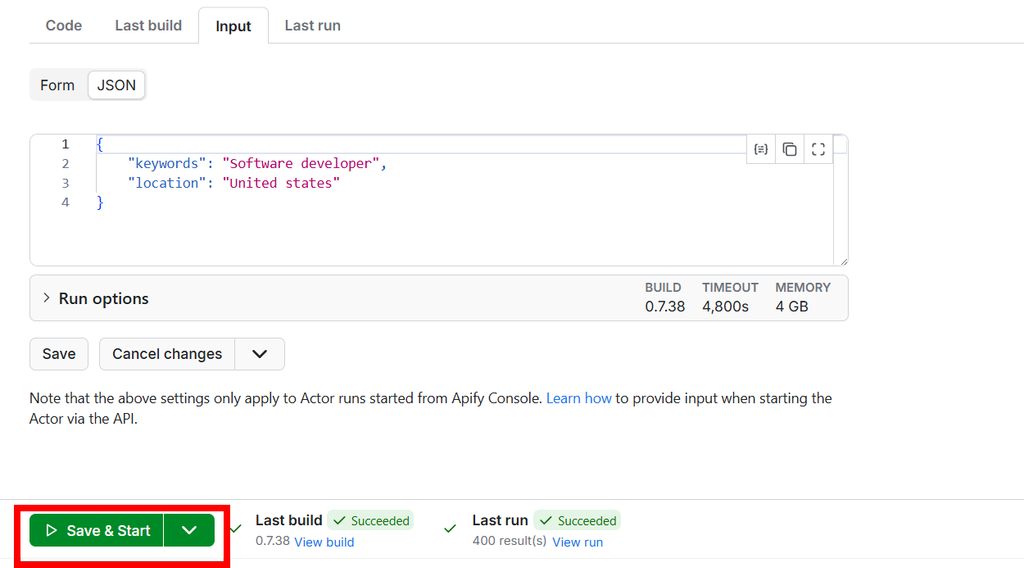
Actor input page
Output Example
The data will be clean, structured, and ready for use.
[ { "title": "software Engineer I", "company": "The Walt Disney Company", "job_url": "https: //www.linkedin.com/jobs/view/software-engineer-i-at-the-walt-disney-company-3970118620?trk=public_jobs_topcard-title", "logo": "https: //media.licdn.com/dms/image/D560BAQGmPH1QqmCzkg/company-logo_100_100/0/1688494223337/fieldguide_inc_logo?e=2147483647&v=beta&t=KqO_GS4C7oH3nVoyvtDCXbbhAvj2OeLbfty0yJYZCbc", "date_posted": "4 days ago", "pay_range": "$98,000.00/yr - $131,300.00/yr", "location": "seattle, WA", "organization": "The Walt Disney Company", "number_of_applicants": "Be among the first 25 applicants", "job_description": "On any given day at Disney Entertainment & ESPN Technology, we’re reimagining ways to create magical viewing experiences for the world’s most beloved stories while also transforming Disney’s media business for the future. Whether that’s evolving our streaming and digital products in new and immersive ways, powering worldwide advertising and distribution to maximize flexibility and efficiency, or delivering Disney’s unmatched entertainment and sports content, every day is a moment to make a difference to partners and to hundreds of millions of people around the world.\n\n\n\nYou will be working on the Developer Experience team under the Consumer Software Engineering organization to build out efficiency tools that bring benefits across developer, QA, product and UX teams. Your contribution will have a broad impact, and it will not only save engineers time and allow them to deliver product features faster, but also help the company save a lot of financial resources. At the same time, you will enjoy fast personal growth while solving exciting and ambitious technical problems!\n\n\n\nYou will have the opportunity to work closely with client developers to build industry leading solutions to enable engineers to remotely access and control streaming devices. You will also build an innovative tool for managing and automating streaming hardware and for creating device labs for Disney engineering teams. Your day to day involves gathering feature requests from users, developing and testing your solutions, and deploying them into production.\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nBachelor’s degree in Computer Science, Information Systems, Software, Electrical or Electronics Engineering, or comparable field of study, and/or equivalent work experience\n\nThe hiring range for this position in Seattle, WA and NY, NY is $98,000 to $131,300 per year based on a 40 hour work week. The amount of hours scheduled per week may vary based on business needs. The base pay actually offered will take intoaccount internal equity and also may vary depending on the candidate’s geographic region, job-related knowledge, skills, and experience among other factors. A bonusand/or long-term incentive units may be provided as part of the compensation package, in addition to the full range of medical, financial, and/or other benefits,dependent on the level and position offered.", "seniority_level": "Mid-Senior level", "employment_type": "Full-time", "job_function": "Information Technology", "industries": "Entertainment Providers" }, { "title": "software Engineer", "company": "Fieldguide", "job_url": "https: //www.linkedin.com/jobs/view/software-engineer-at-fieldguide-3961092714?trk=public_jobs_topcard-title", "logo": "https: //media.licdn.com/dms/image/D560BAQGmPH1QqmCzkg/company-logo_100_100/0/1688494223337/fieldguide_inc_logo?e=2147483647&v=beta&t=KqO_GS4C7oH3nVoyvtDCXbbhAvj2OeLbfty0yJYZCbc", "date_posted": "2 weeks ago", "pay_range": "$125,000.00/yr - $167,000.00/yr", "location": "san Francisco, CA", "organization": "Fieldguide", "number_of_applicants": "Be among the first 25 applicants", "job_description": "About Us:\n\nFieldguide is establishing a new state of trust for global commerce and capital markets through automating and streamlining the work of assurance and audit practitioners specifically within cybersecurity, privacy, and ESG (Environmental, Social, Governance). Put simply, we build software for the people who enable trust between businesses.\n\nWe’re based in San Francisco, CA, but built as a remote-first company that enables you to do your best work from anywhere. We\"re backed by top investors including Bessemer Venture Partners, 8VC, Floodgate, Y Combinator, DNX Ventures, Global Founders Capital, Justin Kan, Elad Gil, and more.\n\nWe value diversity — in backgrounds and in experiences. We need people from all backgrounds and walks of life to help build the future of audit and advisory. Fieldguide’s team is inclusive, driven, humble and supportive. We are deliberate and self-reflective about the kind of team and culture that we are building, seeking teammates that are not only strong in their own aptitudes but care deeply about supporting each other\"s growth.\n\nAs an early stage start-up employee, you’ll have the opportunity to build out the future of business trust. We make audit practitioners’ lives easier by eliminating up to 50% of their work and giving them better work-life balance. If you share our values and enthusiasm for building a great culture and product, you will find a home at Fieldguide.\n\n\n\nAs a Software Engineer at Fieldguide, you’ll be an early member of the team, taking a front-row seat as we build both the company and the engineering organization to tackle the massive and archaic audit and advisory industry.\n\n\n\n\n\n\n\n\n\n\n\nFieldguide is a values-based company. Our values are:\n\n\n\n\n\n\n\nCompensation Range: $125K - $167K", "seniority_level": "Entry level", "employment_type": "Full-time", "job_function": "Engineering and Information Technology", "industries": "software Development" }, // ... more jobs ]
If you need the data in formats other than JSON, Apify allows you to export your dataset to various formats, including CSV, Excel, XML, and more.
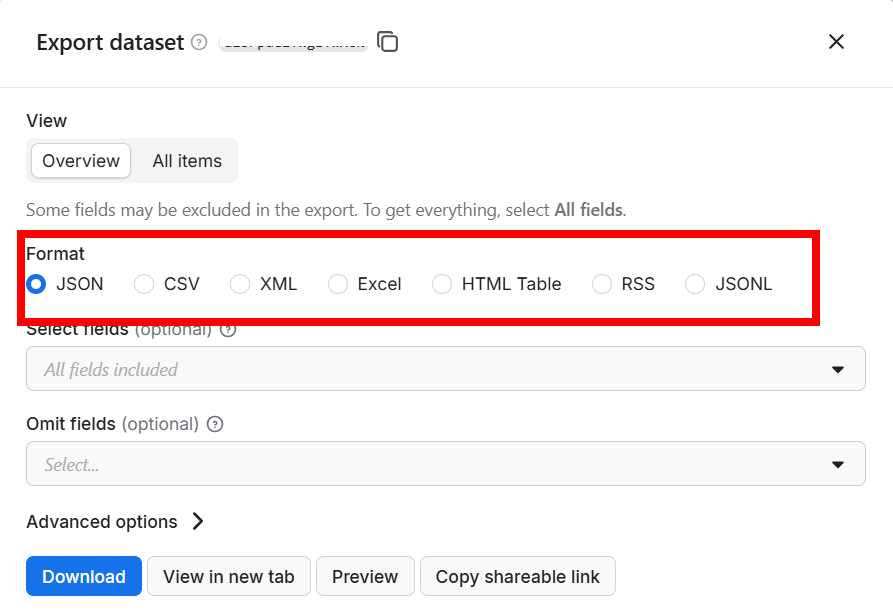
Export data to multiple formats
Wrapping Up
Building your own scraper is a great learning experience, but maintaining it against the constant changes to the LinkedIn website and anti-scraping measures can be a full-time job.
If you need a reliable, maintenance-free solution that handles proxy rotation, scaling, and data parsing for you, try the LinkedIn Job Postings Scraper on Apify today. It is designed to be fast, efficient, and easy to integrate into your existing workflows.
Resources

Emmanuel Uchenna
@eunit99Hi, I’m Emmanuel Uchenna — a frontend engineer, technical writer, and digital health advocate passionate about building technology that empowers people. With over five years of experience, I specialize in crafting clean, scalable user interfaces with React, Next.js, and modern web tooling, while also translating complex technical ideas into clear, engaging content through articles, documentation, and whitepapers.


